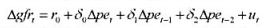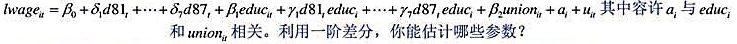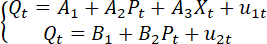题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
考虑例10.6中那种形式的费尔模型。现在,我们不去预测民主党在两党选举中的得票比例,而去估计一
个表示民主党是否获胜的线性概率模型。
(i)用虚拟变量dem wins来代替式(10.23)中的dem vote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果den wins>0.5, 你就可以预测民主党会获胜:否则, 共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健1检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。t统计量有什么明显的变化吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“考虑例10.6中那种形式的费尔模型。现在,我们不去预测民主党…”相关的问题
更多“考虑例10.6中那种形式的费尔模型。现在,我们不去预测民主党…”相关的问题
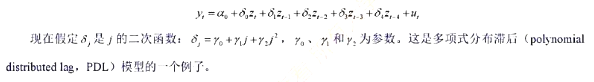
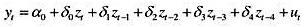
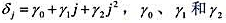 为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。