 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
大数据作为一种数据集合,当我们使用这个概念的时候,实际包含有哪几层含义。()
A.数据很大
B.构成复杂
C.变化很快
D.蕴含大价值
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.数据很大
B.构成复杂
C.变化很快
D.蕴含大价值
如果结果不匹配,请 联系老师 获取答案
 更多“大数据作为一种数据集合,当我们使用这个概念的时候,实际包含有…”相关的问题
更多“大数据作为一种数据集合,当我们使用这个概念的时候,实际包含有…”相关的问题
A.③①②⑤④⑥
B.⑤④③①⑥②
C.③⑤②①④⑥
D.⑤③④⑥①②(2017国家公务员考试行测真题)
参考第3章习题14。现在,我们使用住房价格的对数作为因变量:

(i)你想在住房增加一个150平方英尺的卧室的情况下, 估计并得到price变化百分比的一个置信区间。以小数形式表示就是θ1=150β1+β2。使用HPRICE1.RAW中的数据去估计θ1。
(ii)用θ1和民β1表达β2,并代入log(price) 的方程。
(iii)利用第(ii)部分中的结果得到θ1的标准误,并使用这个标准误构造一个95%的置信区间。
本题利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型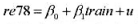 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re 78-re 75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train 78-train75, 那么,由于train75=0,所以ctran=train78。)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
A.对数据库插入新数据,修改和检索原有数据均能按一种公用的和可控制的方式进行
B.数据库中的这些数据是结构化的,无有害的或不必要的冗余,并为多种应用服务。数据的存储独立于使用它的程序
C.当某个系统中存在结构上完全分开的若干个数据库时,则该系统包含一个"数据库集合”
D.数据库是存储在一起的相关数据的集合
A.海量的数据规模、快速的数据流转、多样的数据类型和价值密度低
B.海量的数据规模、低速的数据流转、多样的数据类型、价值密度低
C.海量的数据规模、快速的数据流转、多样的数据类型和价值密度高
D.海量的数据规模、低速的数据流转、多样的数据类型和价值密度高
A.MapReduce是处理大量半结构化数据集合的编程模型
B.MapReduce和Hadoop是相互独立的
C.MapReduce使用一种集合语言执行查询
D.MapReduce是Map和Reduce的两部分用户程序组成
A.数据集合扩充
B.L1和L3正则化
C.提前停止训练
D.使用Dropout方法
利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型re78=β0+β1train+u,并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re78-re75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train78-train75,那么,由于train75=0,所以ctrain=train78.)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。

















