 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
过拟合问题是模型在训练集表现较好,但在测试集表现较差,为了避免过拟合问题,我们可以采取以下哪些方法?()
A.数据集合扩充
B.L1和L3正则化
C.提前停止训练
D.使用Dropout方法
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.数据集合扩充
B.L1和L3正则化
C.提前停止训练
D.使用Dropout方法
如果结果不匹配,请 联系老师 获取答案
 更多“过拟合问题是模型在训练集表现较好,但在测试集表现较差,为了避…”相关的问题
更多“过拟合问题是模型在训练集表现较好,但在测试集表现较差,为了避…”相关的问题
A.与顾客已有广泛接触,拥有广泛顾客群
B.业务代表会全力倾注于公司的产品上
C.业务代表受过较好的训练
D.由于业务代表前途维系于公司的发展,他们表现比较积极
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0+α1Xi+νi,试评述这一设定误差的后果。
(2)在(1)中,假设真实的模型是带截距项的模型,而你却对过原点的模型进行了普通最小二乘回归。请评述这一模型误设的后果。
A.使用更长的历史数据进行回测
B.使用较短的历史数据进行回测
C.在策略设计的时候有意地增加参数数量
D.将历史数据分为样本内和样本外两部分进行测试
(i)用混合OLS估计一个以学期GPA(trmgpa)为因变量的模型。解释变量是sprng,sat,hsperc,feale,black,white,frestsem,tothrs,crsgpa和season。试解释season的系数。它统计显著吗?
(ii)在仅参与秋季运动项目的运动员中,大多数是足球运动员。假定足球运动员的能力水平和其他运动员的能力水平有系统差异。如果SAT分数和中学成绩百分位数不能很好地反映一个人的能力水平,那么混合OLS估计量将是有偏误的。试解释。
(iii)现在,取两个学期数据的差分,问哪些变量将随之消失?现在检验赛季效应。
(iv)你能想象一个或多个有潜在重要性而又不随时间而变化的变量,在此分析中被我们忽略了吗?
在10.3节酶促反应中,如果用指数增长模型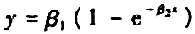 代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型
代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型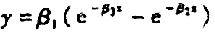 来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。

















