 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题利用TRAFFIC 2.RAW中的数据。前面的计算机习题C 10.11曾要求你分析这些数据。(i)计算变量prc
本题利用TRAFFIC 2.RAW中的数据。前面的计算机习题C 10.11曾要求你分析这些数据。(i)计算变量prc
本题利用TRAFFIC 2.RAW中的数据。前面的计算机习题C 10.11曾要求你分析这些数据。
(i)计算变量prc fat的一阶自相关系数。你认为prc fat包含单位根吗?失业率也一样吗?
(ii)估计一个将prc fal的一阶差分Aprcfat与计算机习题C10.11第(vi) 部分中同样变量相联系的多元回归模型,只是你还应该对失业率进行一阶差分。于是,模型中包含一个线性时间趋势、月度虚拟变量、周末变量和两个政策变量:不要将这些变量进行差分。你发现了什么有意思的结论吗?
(iii)评论如下命题:“在进行多元回归之前,我们总应该将怀疑具有单位根的时间序列进行一阶差分,因为这样做是一种安全策略,而且应该得到与使用水平值类似的结论。”[在回答这个问题时,最好先做(如果你还没有做过的话)计算机习题C10.11第(vi)部分中的回归。]
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“本题利用TRAFFIC 2.RAW中的数据。前面的计算机习题…”相关的问题
更多“本题利用TRAFFIC 2.RAW中的数据。前面的计算机习题…”相关的问题
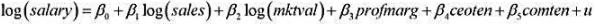

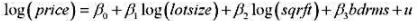
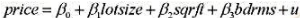

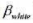 的95%的置信区间与非稳健的置信区间相比较。
的95%的置信区间与非稳健的置信区间相比较。

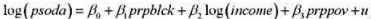
 。
。















