

 如果结果不匹配,请
如果结果不匹配,请 
 更多“错误I的大小用犯错误I的概率来衡量,通常用()来表示。A.α…”相关的问题
更多“错误I的大小用犯错误I的概率来衡量,通常用()来表示。A.α…”相关的问题
关于I型错误与Ⅱ型错误,说法正确的是()。
A.若“拒绝H0”,犯错误的可能性为β
B.拒绝了实际成立的H0所犯的错误为I型错误
C.对同一资料,I型错误与Ⅱ型错误的概率大小没有联系
D.若想同时减少I型错误与Ⅱ型错误的概率,只有减少样本含量行
E.若“不拒绝H0”,不可能犯Ⅱ型错误
(i)用虚拟变量demwins来代替教材(10.23)中的demvote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果demwins>0.5,你就可以预测民主党会获胜;否则,共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健:检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。!统计量有什么明显的变化吗?
利用PNTSPRD.RAW中的数据。
(i)变量favwin是一个二值变量,在拉斯维加斯所押的球队胜出了预定的分数差时取值1。估计所押球队获胜概率的线性概率模型为
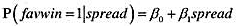
如果分数差包括了所有相关的信息,那我们预期β0=0.5。请解释。
(ii)用OLS估计第(i)部分的模型。相对于双侧备择假设检验H0:β0=0.5。同时使用通常的标准误和异方差一稳健的标准误。
(iii)spread在统计上显著吗?当spread=10时,被押球队获胜的估计概率是多少?
(iv)现在对P(favwin=Ilspread)估计一个概率单位模型。解释和检验截距项为0的虚拟假设。[提示:注意Φ(0)=0.5。]
(v)利用概率单位模型估计当spread=10时被押球队获胜的概率。并与第(iii)部分的LPM估计值相比较。
(vi)在概率单位模型中增加变量fuvhome、fav25和und25,并用似然比检验来检验这些变量的联合显著性。(x2分布中的自由度是多少?)解释这个结果,注意分数差是否包括了赛前可观测到的全部信息这个问题。
(i)用虚拟变量dem wins来代替式(10.23)中的dem vote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果den wins>0.5, 你就可以预测民主党会获胜:否则, 共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健1检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。t统计量有什么明显的变化吗?
A.同时减少两类错误发生的概率
B.同时增加两类错误发生的概率
C.增加I类错误发生的概率,同时减少II类发生的概率
D.增加I类错误发生的概率,同时减少II类错误发生的概率
E.对两类错误发生概率没什么影响
















