 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
使用WAGE2.RAW中的数据。 (i)在教材例9.3中,用变量KWW(“工作领域内知识”测试分数)取代IQ作为能
使用WAGE2.RAW中的数据。
(i)在教材例9.3中,用变量KWW(“工作领域内知识”测试分数)取代IQ作为能力的代理变量。在此情形下,估计的教育回报是多少?
(ii)现在用IQ和KWW一起作为代理变量。所估计的教育回报会怎么样?
(iii)在第(ii)部分中,IQ和KWW是个别显著的吗?它们联合显著吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“使用WAGE2.RAW中的数据。 (i)在教材例9.3中,用…”相关的问题
更多“使用WAGE2.RAW中的数据。 (i)在教材例9.3中,用…”相关的问题
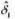

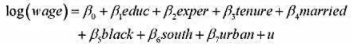
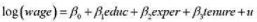
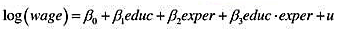
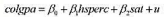
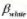 看起来对所使用的样本过度敏感吗?
看起来对所使用的样本过度敏感吗?















